CourseKata Chapter 11
Model Significance (1)
Example 1: Categorical Explanatory
\[Y_A\sim N(20, 3), \quad Y_B\sim N(20, 3), \quad n_1=n_2=10\]
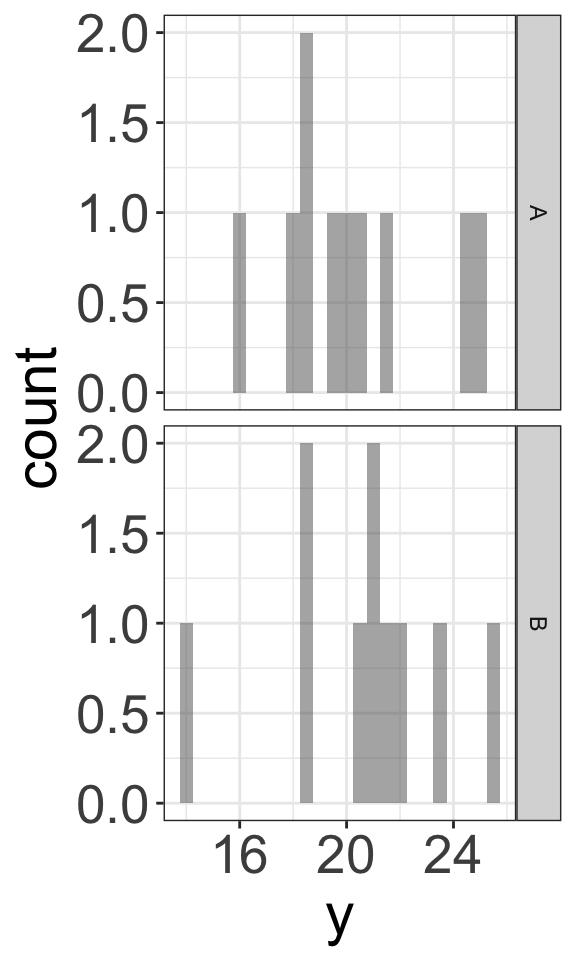
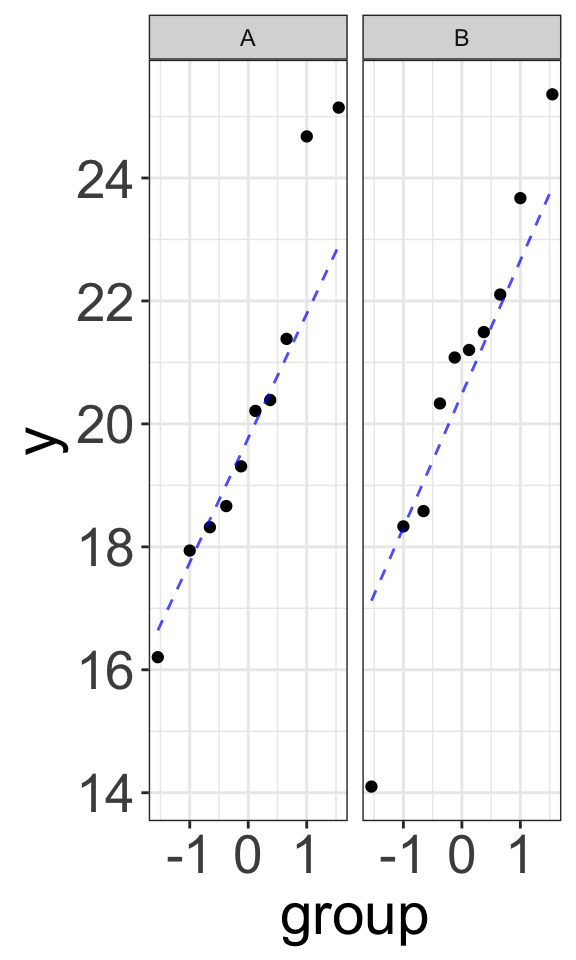
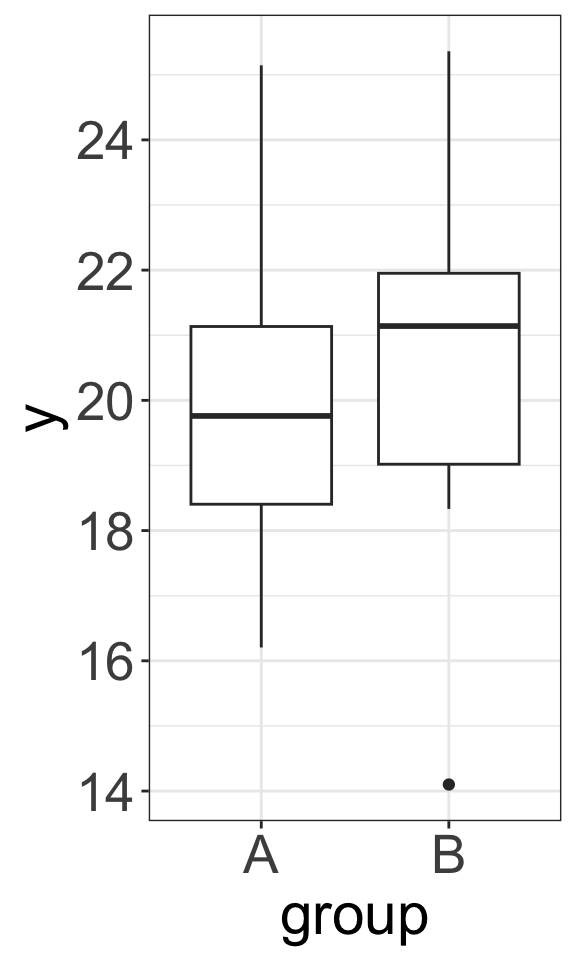
Example 1: Null Distributions
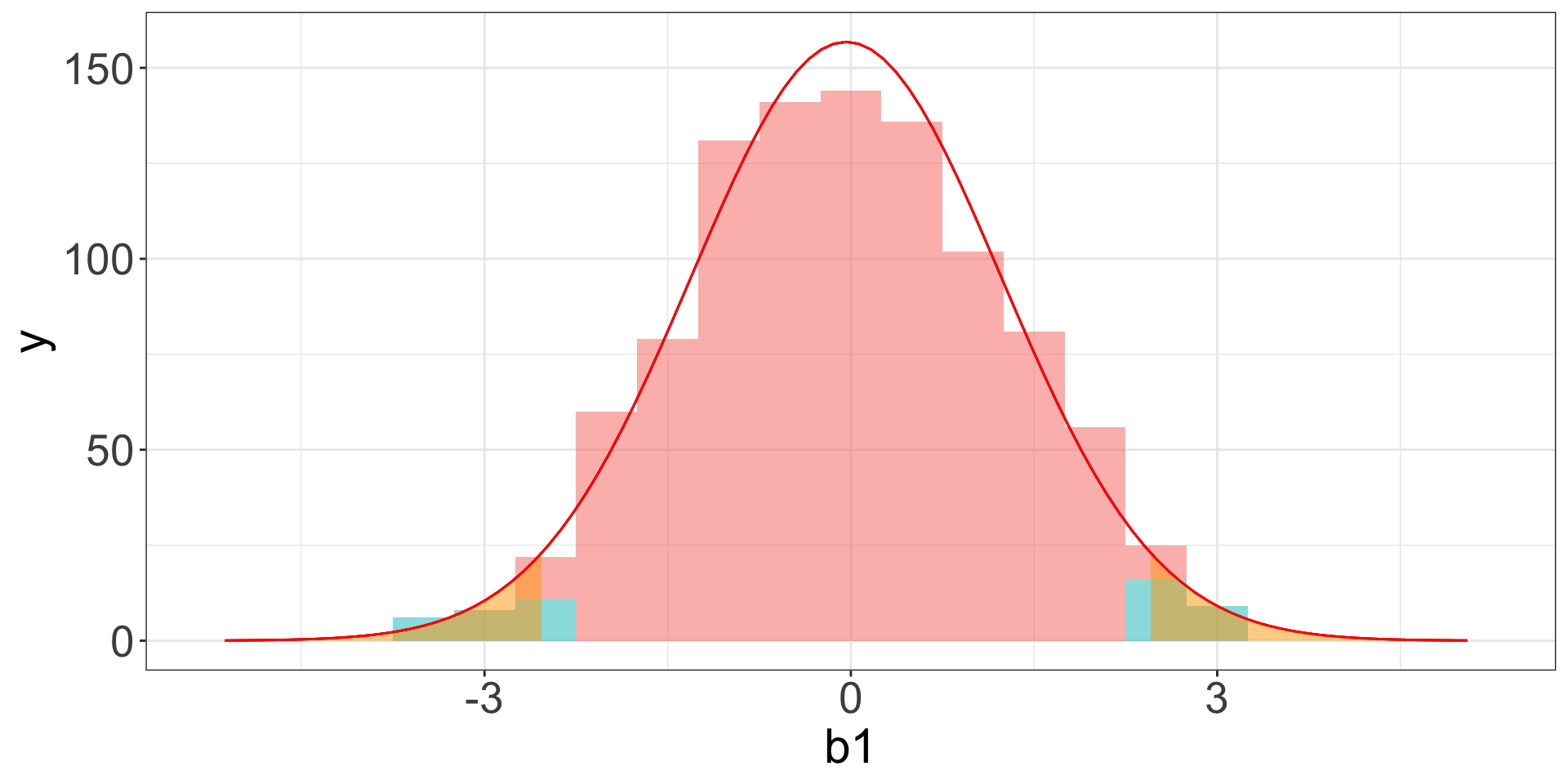
Example (2): Different Variance
\[Y_A\sim N(20, 6), \quad Y_B\sim N(20, 3), \quad n_1=n_2=10\]
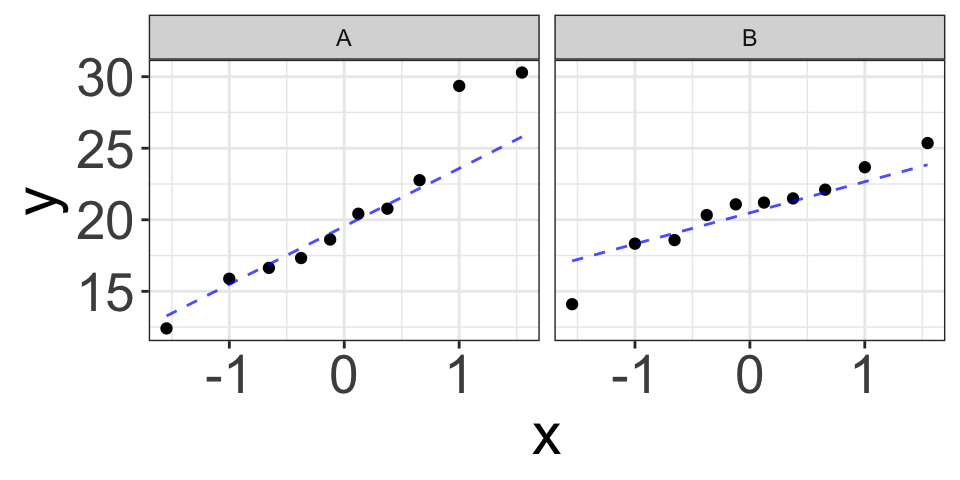
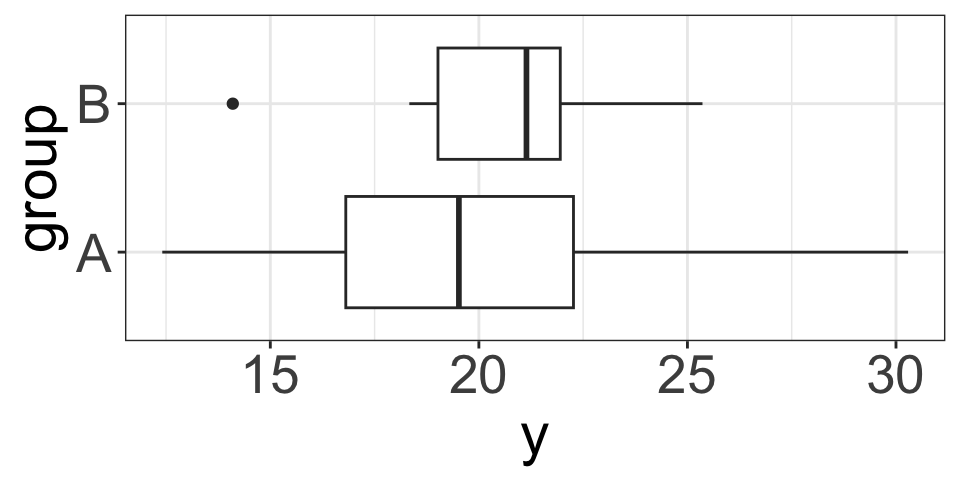
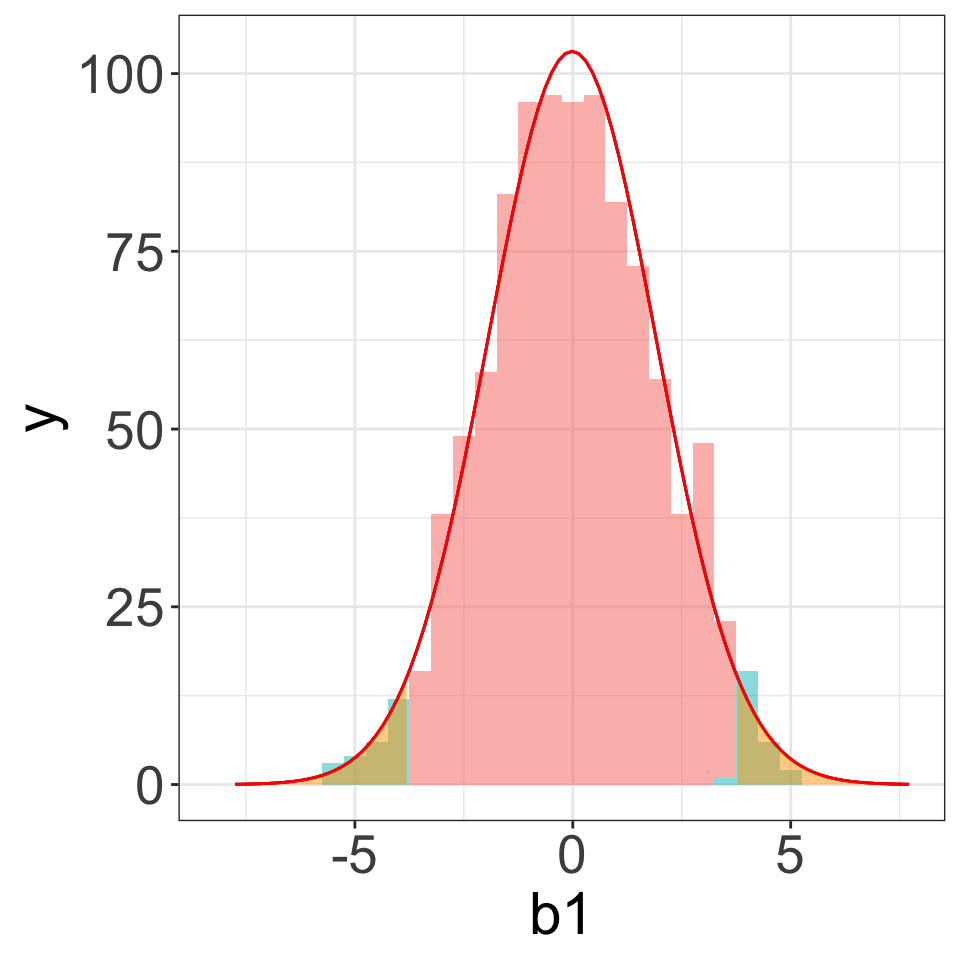
Example (3): Unbalanced Data
\[Y_A\sim N(20, 6), \quad Y_B\sim N(20, 3), \quad n_1=10, n_2=15\]
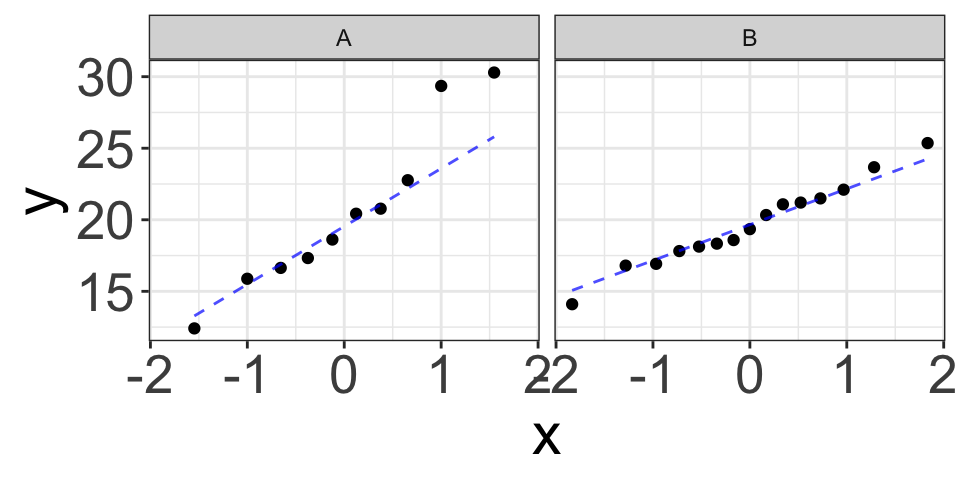
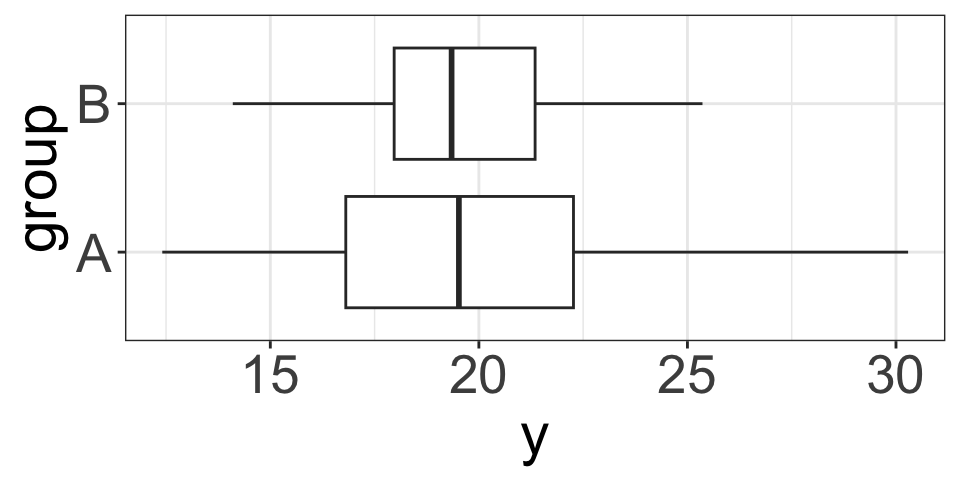
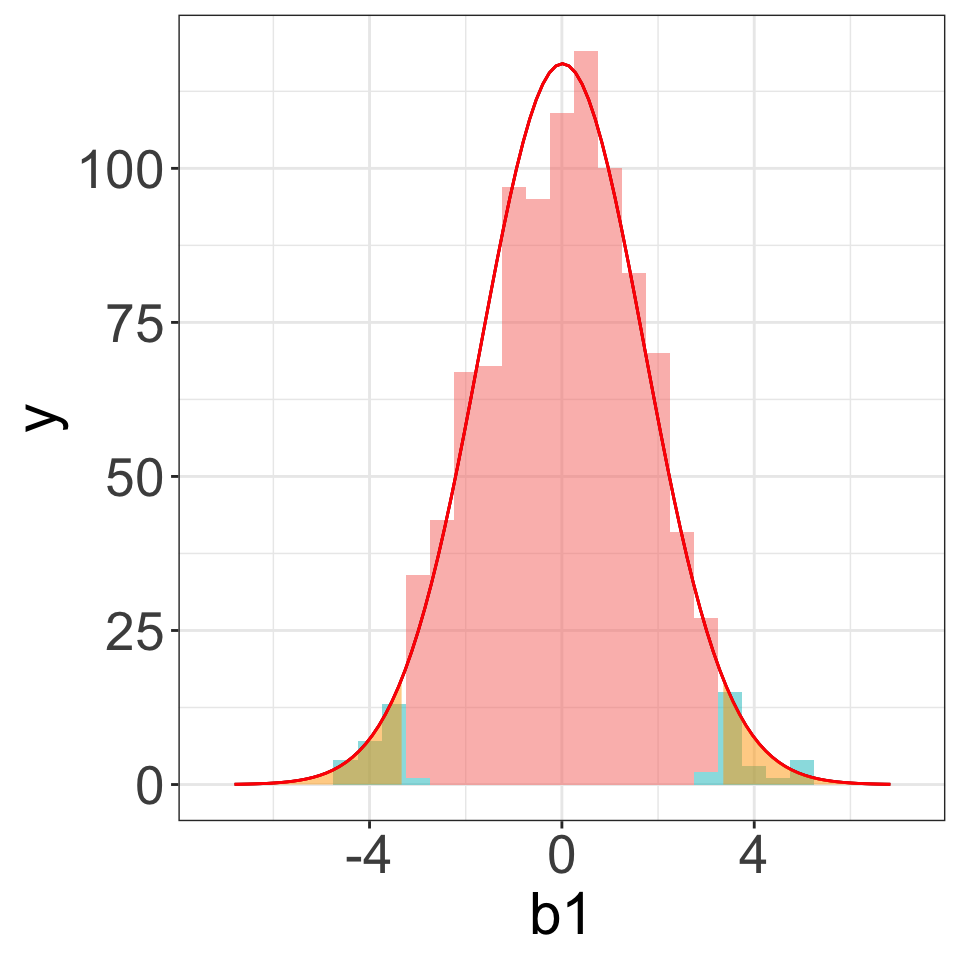
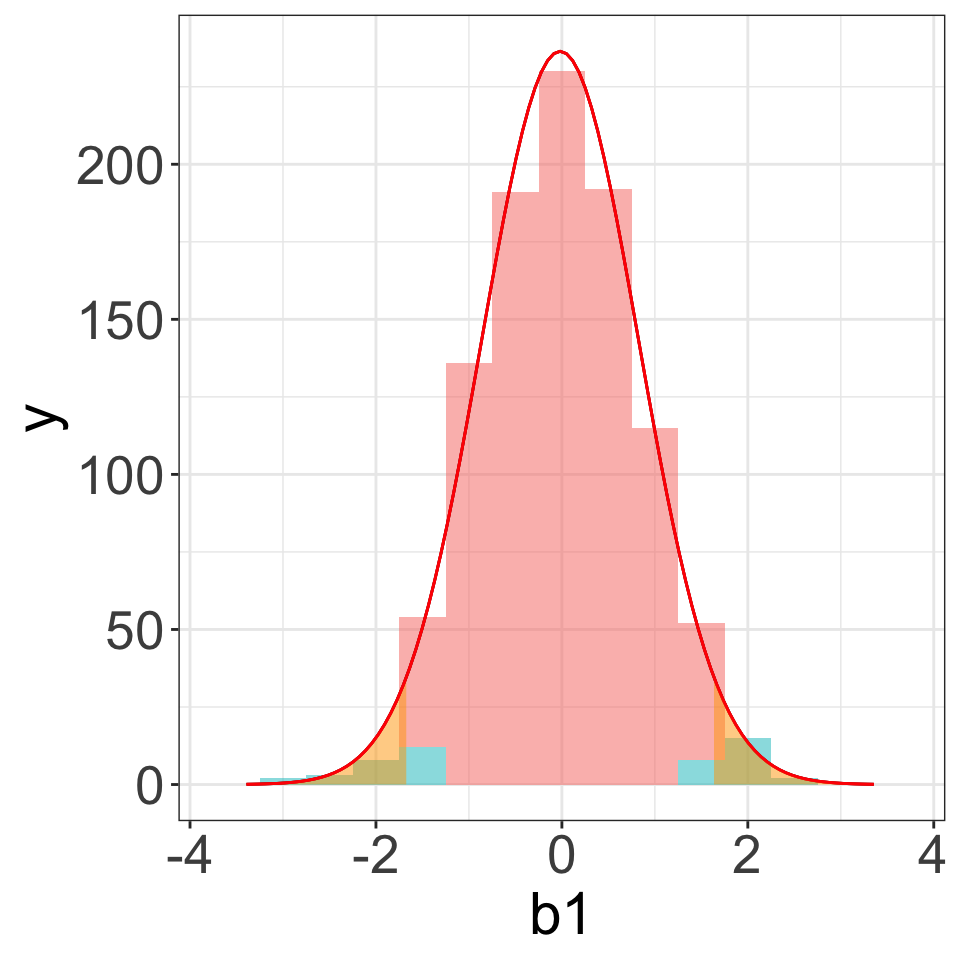
Example (4): Skewed Distribution
\[Y_A\sim N(20, 3), \quad Y_B\sim \text{skewed right}, \quad n_1=10, n_2=15\]
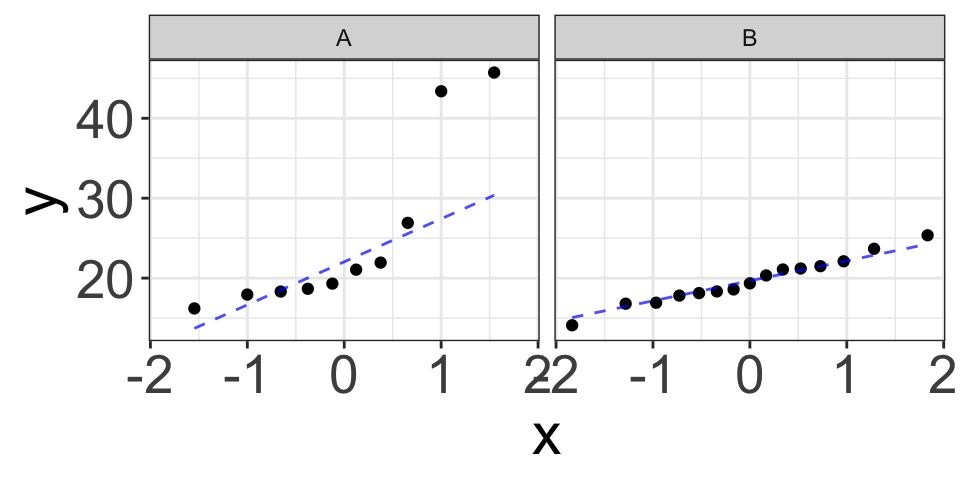
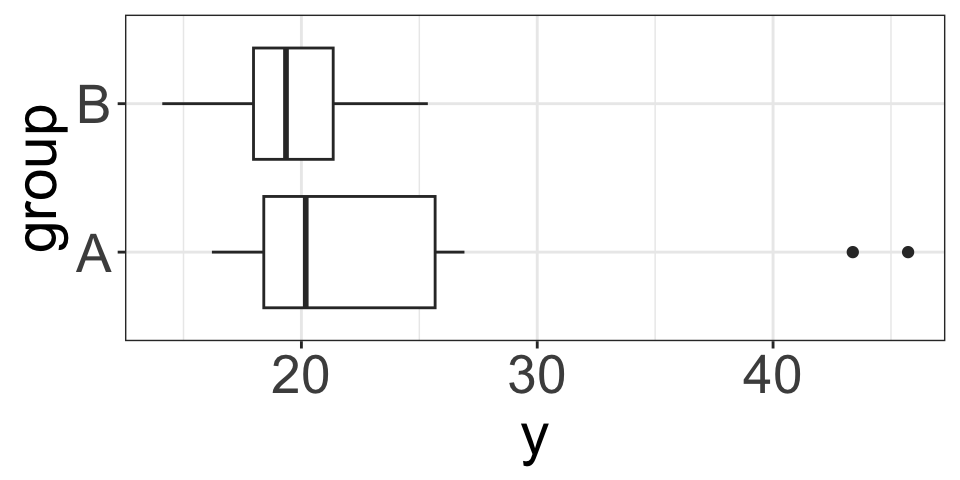
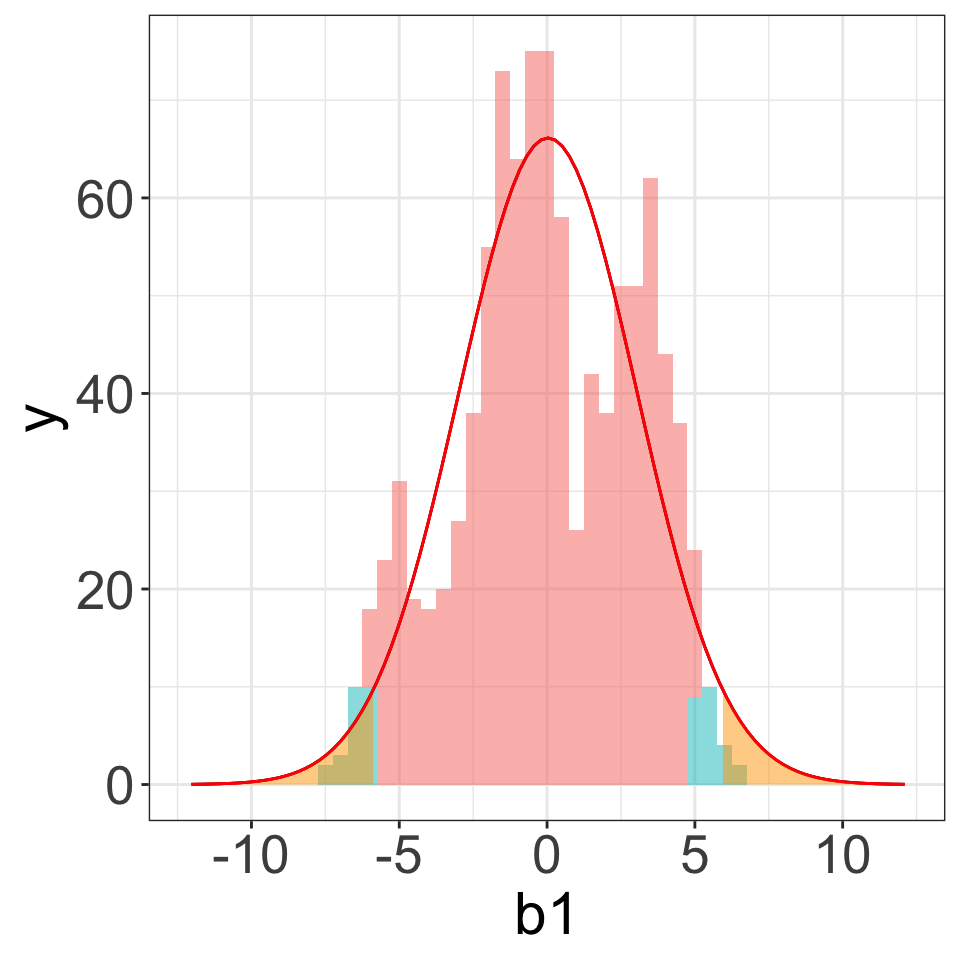
Example (5): Skewed & large \(n\)
\[Y_A\sim N(20, 3), \quad Y_B\sim \text{skewed right}, \quad n_1=100, n_2=150\]
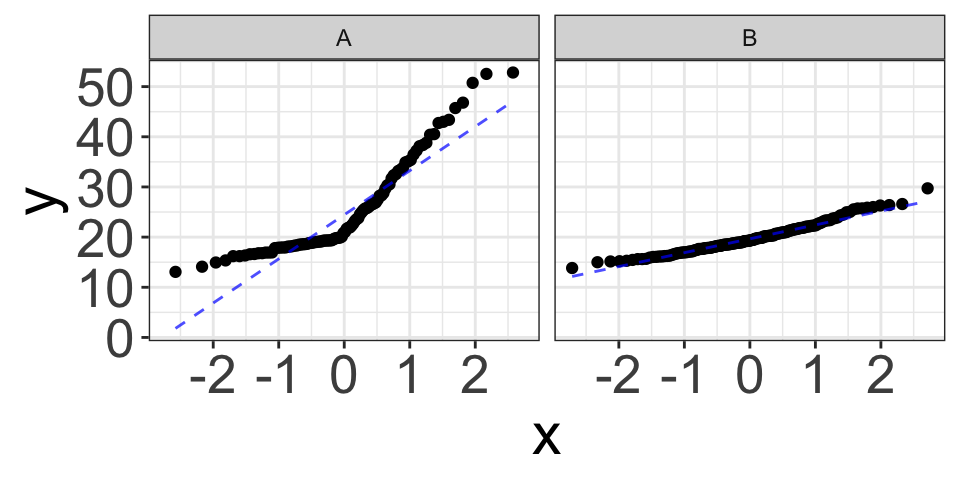
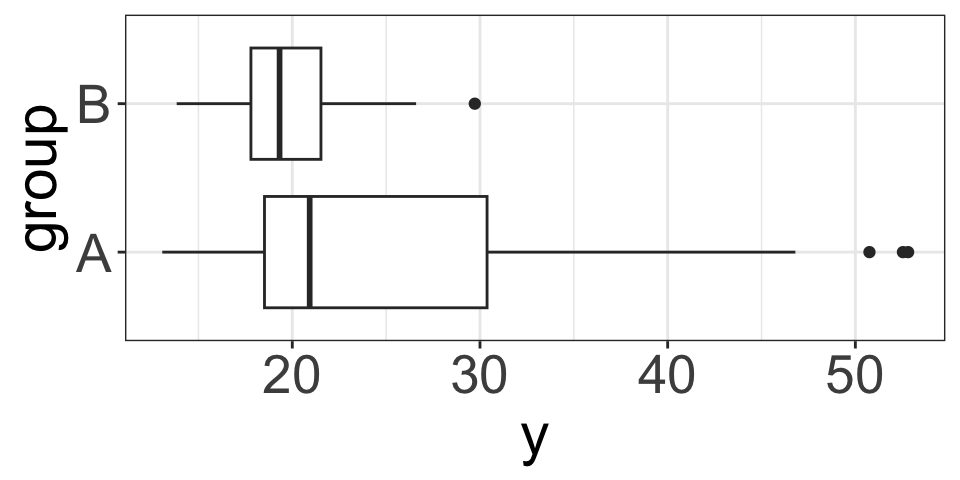
Thumb~Gender Example
\[Thumb=\beta_0+\beta_1 Gender_{Male} + \varepsilon\] - \(H_0: \beta_1=0\) vs. \(H_a: \beta_1\ne 0\)
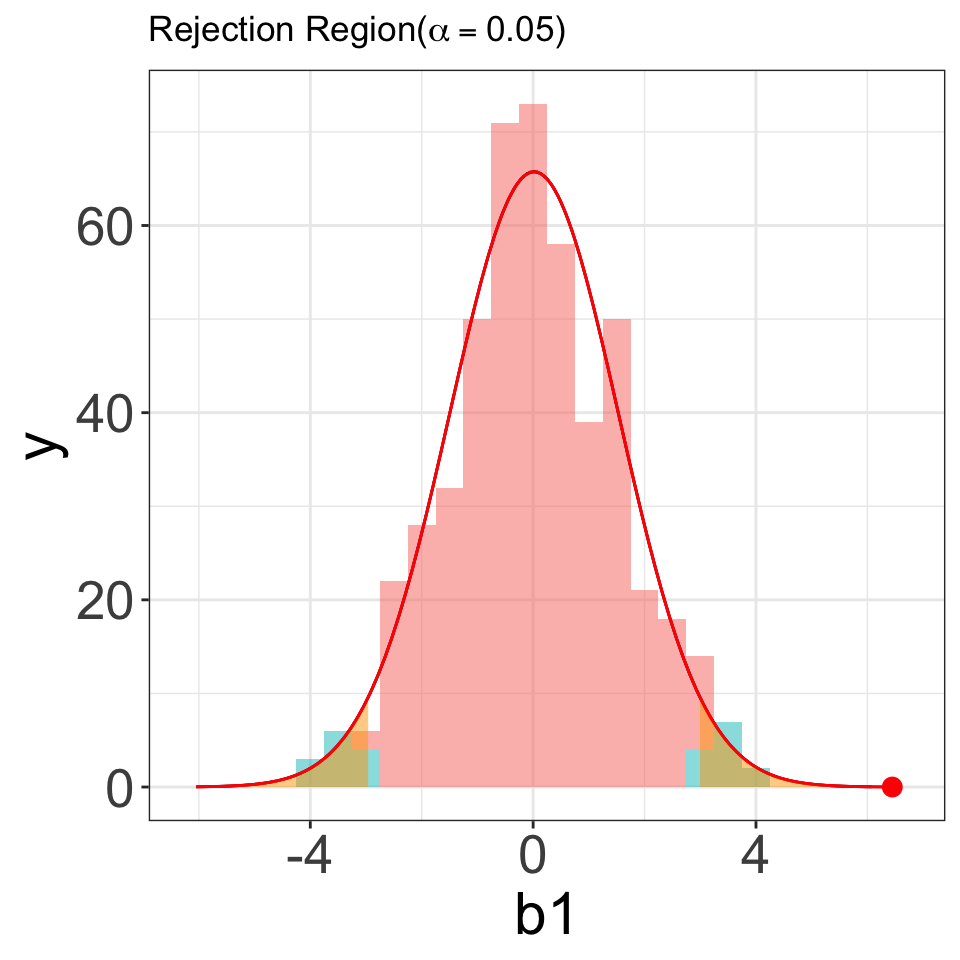
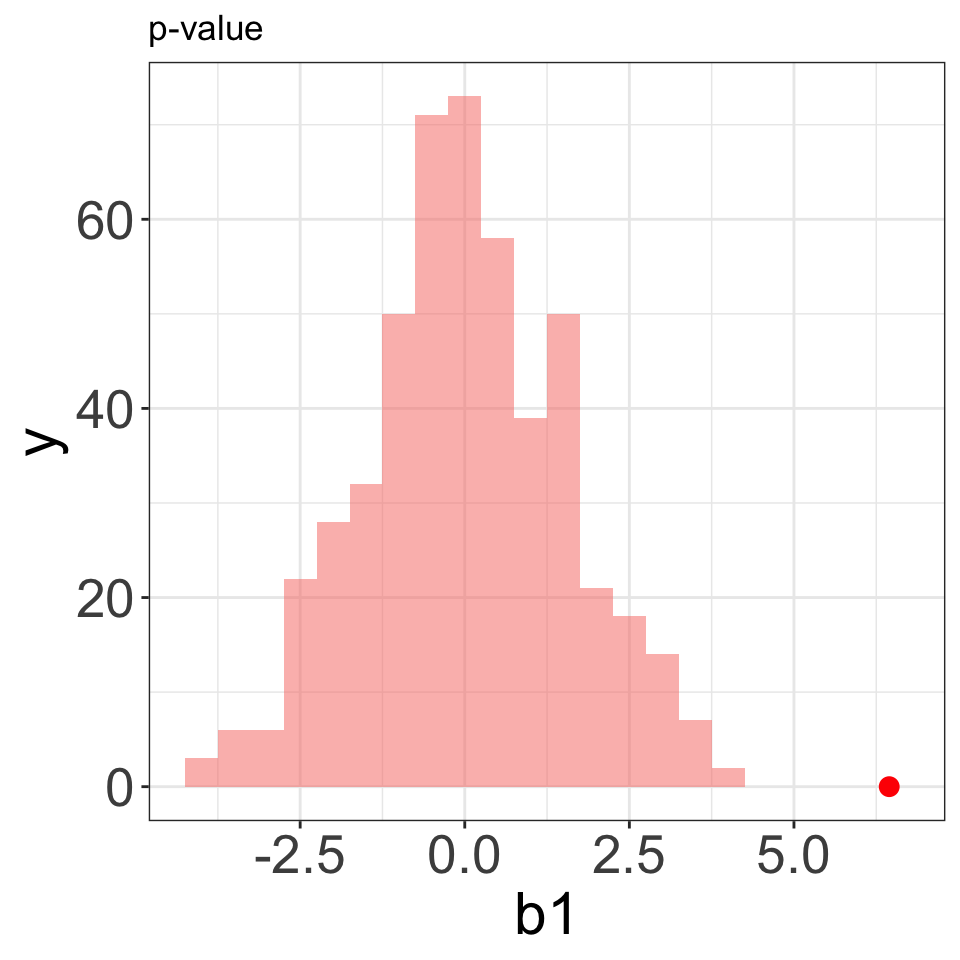
Probability of getting a result this extreme (or more) if the null is true